python爬取四六级成绩
![]()
号外
今天四级成绩刚出来,辅导员就叫我把全院的四级成绩爬下来,为此我还翘掉了一节离散数学,浪费了一节微积分 T_T
四级成绩有三个网址可以查
教育部查询需要验证码,代码复杂度不是一个级别,首先抛弃。
如果选择爬取学信网
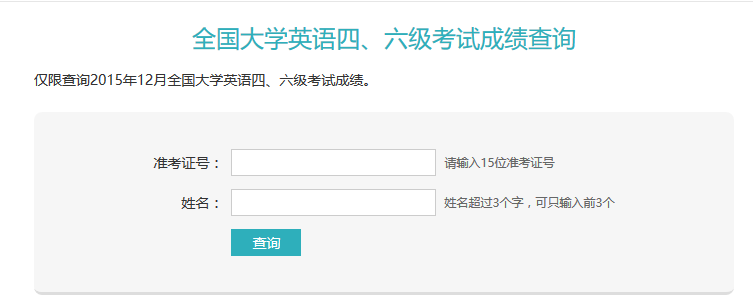
首先填写信息,用FireBug抓包
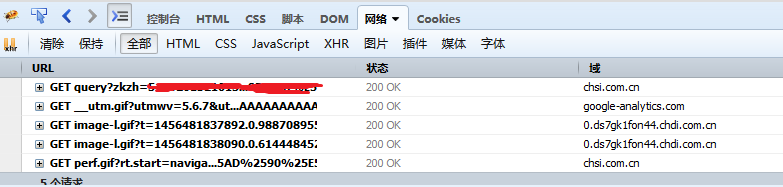

采取的是GET方式,有两个参数,分别是zkzh和xm
用HackBar测试

发现并不能正常查询,查看之前抓的包,怀疑是Referer作祟
补上Referer
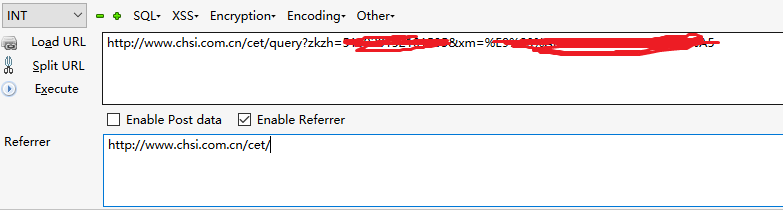
这样搞清楚了就很简单了。
代码如下
import requests
import re
#自定义头文件
header={'Referer':'http://www.chsi.com.cn/cet/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0',
'Host':'www.chsi.com.cn'}
#学信网的url
url="http://www.chsi.com.cn/cet/query"
#name.txt是含有姓名和准号证号(15位)的txt,排列规则为每一行:准考证号 姓名,例如:500000000000000 张三
data_in=open("name.txt","r+",encoding='utf-8')
text=data_in.readlines()
#读取每一行的准考证号和姓名
for line in text:
#去掉末尾空格
line=line.strip('\n')
#准考证号为15位
num=line[0:15]
#如果名字是2个字,取这两个字,如果大于等于三个字,取前三个字(学信网姓名一栏仅让输入3个字)
if len(line)<18:
name=line[16:18]
else:
name=line[16:19]
#添加参数
param={
'zkzh':num,
'xm':name
}
#构造get
responce=requests.get(url,headers=header,params=param)
#为了方便正则表达式找总分,去掉所有换行符
newtext=responce.text.replace('\n','')
try:
#正则表达式找到总分
score=re.findall('.*?(\d+)',newtext)
#输出“姓名+总分”字符串
ans=name+" "+score[0]
#打印该字符串
print(ans)
except:
#打印未能成功爬取的人
print("Error:",num," ",name)
值得注意的是
爬取过程中学信网将会不时要求输入验证码,这种情况下程序会卡住或崩溃,不过并无大碍,存下已经爬取的信息,更新name.txt,继续爬取即可。
99宿舍很方便爬取,其名字使用的GBK编码,在python里encode一下即可,不做详细记录,分析步骤同学信网一样,99宿舍的爬取更加快速和方便。
import requests
import re
import xlwt
#自定义头文件
header={'Referer':'http://cet.99sushe.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0',
'Host':'cet.99sushe.com'}
#99宿舍的url
url="http://cet.99sushe.com/findscore"
#name.txt是含有姓名和准号证号(15位)的txt,排列规则为每一行:准考证号 姓名,例如:500000000000000 张三
data_in=open("name.txt","r+",encoding='utf-8')
text=data_in.readlines()
#使用xlwt模块写入xls
wb=xlwt.Workbook(encoding='utf-8')
xm=wb.add_sheet('四级成绩',cell_overwrite_ok=True)
xm.write(0,0,'姓名')
xm.write(0,1,'听力')
xm.write(0,2,'阅读')
xm.write(0,3,'写作及翻译')
xm.write(0,4,'总分')
#tot代表行数
tot=1
#将获取失败的帐号写入error.txt
error=open("error.txt","w",encoding='utf-8')
#读取每一行的准考证号和姓名
for line in text:
#去掉末尾空格
line=line.strip('\n')
#准考证号为15位
num=line[0:15]
#取名字前2个字(99宿舍姓名一栏仅让输入2个字)
name=line[16:18]
#添加参数
param={
'id':num,
'name':name.encode('gbk')
}
#构造get
responce=requests.post(url,headers=header,data=param)
try:
#找到每一项成绩
score=re.findall('\d,(\d+),(\d+),(\d+),(\d+),电子科技大学,(\w\w+)',responce.text)
print(tot,":",score[0][4])
#分别写入xls
xm.write(tot,0,score[0][4])
xm.write(tot,1,score[0][0])
xm.write(tot,2,score[0][1])
xm.write(tot,3,score[0][2])
xm.write(tot,4,score[0][3])
tot=tot+1
except:
#获取失败的写入error.txt
ans=num+" "+name
error.writelines(ans+"\n")
print("Error:",num,name)
#最后别忘了保存xls
wb.save('CET4.xls')
值得注意的是
99宿舍更方便爬取,建议使用