CVE-2022-27666: Exploit esp6 modules in Linux kernel
![]()
Written by Xiaochen Zou and Zhiyun Qian
University of California, Riverside
This post discloses the exploit of CVE-2022-27666, a vulnerability that achieves local privilege escalation on the latest Ubuntu Desktop 21.10. By the time we posted this writeup, all the distros have patched this vulnerability.
Our preliminary experiment shows this vulnerability affects the latest Ubuntu, Fedora, and Debian. Our exploit was built to attack Ubuntu Desktop 21.10 (The latest version while I was writing the exploit).
The exploit achieve around 90% reliability on fresh installed Ubuntu Desktop 21.10 (VMware’s default setup: 4G mem, 2 CPU), we manage to come up with some novel heap stable tricks to mitigate the kernel heap noise. For the exploit technique, it’s my first time doing page-level heap fengshui and cross-cache overflow, and I choose msg_msg’s arb read & write to leak the KASLR offset and escalate the privilege. I’ve learned so much during writing this exploit and hope you have fun reading it.
Root Cause
CVE-2022-27666 is a vulnerability in Linux esp6 crypto module, it was introduced in 2017, by commit cac2661c53f3 and commit 03e2a30f6a27. The basic logic of this vulnerability is that the receiving buffer of a user message in esp6 module is an 8-page buffer, but the sender can send a message larger than 8 pages, which clearly creates a buffer overflow.
esp6_output_head takes charge of allocating the receiving buffer, the allocsize isn’t important here, skb_page_frag_refill by default allocates an 8-page contiguous buffer at line 9.
int esp6_output_head(struct xfrm_state *x, struct sk_buff *skb, struct esp_info *esp)
{
...
int tailen = esp->tailen;
allocsize = ALIGN(tailen, L1_CACHE_BYTES);
spin_lock_bh(&x->lock);
if (unlikely(!skb_page_frag_refill(allocsize, pfrag, GFP_ATOMIC))) {
spin_unlock_bh(&x->lock);
goto cow;
}
...
}
bool skb_page_frag_refill(unsigned int sz, struct page_frag *pfrag, gfp_t gfp)
{
if (pfrag->offset + sz <= pfrag->size)
return true;
...
if (SKB_FRAG_PAGE_ORDER &&
!static_branch_unlikely(&net_high_order_alloc_disable_key)) {
pfrag->page = alloc_pages((gfp & ~__GFP_DIRECT_RECLAIM) |
__GFP_COMP | __GFP_NOWARN |
__GFP_NORETRY,
SKB_FRAG_PAGE_ORDER);
...
}
...
return false;
}skb_page_frag_refill allocates order-3 pages, which is an 8-page contiguous buffer. Therefore, the maximum size of the receiving buffer is 8 pages, and the incoming data can be larger than 8 pages, so it creates a buffer overflow in null_skcipher_crypt. In this function (line 11), kernel copies an N-pages data to an 8 pages buffer, which clearly causes an out-of-bounds write.
static int null_skcipher_crypt(struct skcipher_request *req)
{
struct skcipher_walk walk;
int err;
err = skcipher_walk_virt(&walk, req, false);
while (walk.nbytes) {
if (walk.src.virt.addr != walk.dst.virt.addr)
// out-of-bounds write
memcpy(walk.dst.virt.addr, walk.src.virt.addr,
walk.nbytes);
err = skcipher_walk_done(&walk, 0);
}
return err;
}Now, let’s look at the patch that fixes this vulnerability. ESP_SKB_FRAG_MAXSIZE is 32768, equal to 8 pages. If the allocsize is bigger than 8 pages, then fallback to COW;
diff --git a/include/net/esp.h b/include/net/esp.h
index 9c5637d41d951..90cd02ff77ef6 100644
--- a/include/net/esp.h
+++ b/include/net/esp.h
@@ -4,6 +4,8 @@
#include <linux/skbuff.h>
+#define ESP_SKB_FRAG_MAXSIZE (PAGE_SIZE << SKB_FRAG_PAGE_ORDER)
+
struct ip_esp_hdr;
static inline struct ip_esp_hdr *ip_esp_hdr(const struct sk_buff *skb)
diff --git a/net/ipv4/esp4.c b/net/ipv4/esp4.c
index e1b1d080e908d..70e6c87fbe3df 100644
--- a/net/ipv4/esp4.c
+++ b/net/ipv4/esp4.c
@@ -446,6 +446,7 @@ int esp_output_head(struct xfrm_state *x, struct sk_buff *skb, struct esp_info *
struct page *page;
struct sk_buff *trailer;
int tailen = esp->tailen;
+ unsigned int allocsz;
/* this is non-NULL only with TCP/UDP Encapsulation */
if (x->encap) {
@@ -455,6 +456,10 @@ int esp_output_head(struct xfrm_state *x, struct sk_buff *skb, struct esp_info *
return err;
}
+ allocsz = ALIGN(skb->data_len + tailen, L1_CACHE_BYTES);
+ if (allocsz > ESP_SKB_FRAG_MAXSIZE)
+ goto cow;
+
if (!skb_cloned(skb)) {
if (tailen <= skb_tailroom(skb)) {
nfrags = 1;
diff --git a/net/ipv6/esp6.c b/net/ipv6/esp6.c
index 7591160edce14..b0ffbcd5432d6 100644
--- a/net/ipv6/esp6.c
+++ b/net/ipv6/esp6.c
@@ -482,6 +482,7 @@ int esp6_output_head(struct xfrm_state *x, struct sk_buff *skb, struct esp_info
struct page *page;
struct sk_buff *trailer;
int tailen = esp->tailen;
+ unsigned int allocsz;
if (x->encap) {
int err = esp6_output_encap(x, skb, esp);
@@ -490,6 +491,10 @@ int esp6_output_head(struct xfrm_state *x, struct sk_buff *skb, struct esp_info
return err;
}
+ allocsz = ALIGN(skb->data_len + tailen, L1_CACHE_BYTES);
+ if (allocsz > ESP_SKB_FRAG_MAXSIZE)
+ goto cow;
+
if (!skb_cloned(skb)) {
if (tailen <= skb_tailroom(skb)) {
nfrags = 1;Exploitability
In our preliminary experiment, we manage to send 16-pages data, which means we create an 8-pages overflow in the kernel space, it’s pretty enough for a generic OOB write. One thing worth mentioning is that esp6 appends several bytes to the tail in function esp_output_fill_trailer. These bytes are calculated from the length of the incoming message and the protocol we are using.
static inline void esp_output_fill_trailer(u8 *tail, int tfclen, int plen, __u8 proto)
{
/* Fill padding... */
if (tfclen) {
memset(tail, 0, tfclen);
tail += tfclen;
}
do {
int i;
for (i = 0; i < plen - 2; i++)
tail[i] = i + 1;
} while (0);
tail[plen - 2] = plen - 2;
tail[plen - 1] = proto;
}The tail calculation is shown above, their values are strictly bound with the length and protocol. we cannot make them be arbitrary values, and therefore we consider the tail bytes are garbage data.
Page-level heap fengshui
Not like any other exploits I developed before, this vulnerability requires a page-level heap fengshui. Remember that OOB write comes from an 8-page contiguous buffer, which means the overflow occurs to the adjacent pages.
Page allocator
Linux page allocator[2], A.K.A. buddy allocator, manages physical pages in Linux kernel. Page allocator maintains lower-level memory management behind memory allocators like SLUB, SLAB, SLOB. One simple example is that when kernel consumes all slabs of kmalloc-4k, the memory allocators would request a new slab/memory from the page allocator, in this case, kmalloc-4k has an 8 pages (order 3) slab so it asks for an 8 pages memory from the page allocator.
Page allocator maintains free pages in a data structure called free_area. It’s an array that keeps different orders/sizes of pages. The term to differentiate page sizes is order. To calculate the size of N-order pages, use PAGE_SIZE << N. In such case, order-0 page equates to 1 page (PAGE_SIZE << 0), order-1 pages equate to 2 pages (PAGE_SIZE << 1) , … , order-3 pages equate 8 pages (PAGE_SIZE << 3). For each order in free_area, it maintains a free_list. Pages are allocated from the free_list and freed back to the free_list.
Different kernel slabs request different orders of pages when the free_list is consumed up. For example, on Ubuntu 21.10, kmalloc-256 requests order-0 page, kmalloc-512 requests order-1 pages, kmalloc-4k requests order-3 pages.
If there are no freed pages in that free_list, the lower-order free_area borrows pages from a higher-order free_area. In that case, higher-order pages split up into two blocks, the lower-address block sent to the pages request source (usually alloc_pages()) , the higher-address block sent to the free_list of the lower order. For example, when order-2 (4 pages) free_list are all consumed up, it requests pages from order-3 (8 pages), the order-3 pages split into two 4-page blocks, the lower-address 4 pages block has been assigned to the object that request those pages, the higher-address 4 pages block was sent to order-2’s free_list, so next time if a process requests order-2 pages again, there would be one available order-2 pages in its free_list.
If there are too many freed pages in a free_list, the page_allocator starts merging two same order and physically adjacent pages into a higher order. Let’s take the same example above to explain. If an order-3 page got split into two order-2 pages, one of them has been allocated and the other stays in order-2’s free_list. Once that allocated pages got freed back to order-2’s free_list, page allocator checks if these newly freed pages have adjacent pages in the same free_list (they are called ‘buddy’), if so, they will be merged into order 3.

The following code snippet shows how the page allocator picks up pages blocks from free_area and how to borrow pages from a higher order.
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
// Pick up the right order from free_area
area = &(zone->free_area[current_order]);
// Get the page from the free_list
page = get_page_from_free_area(area, migratetype);
// If no freed page in free_list, goes to high order to retrieve
if (!page)
continue;
del_page_from_free_list(page, zone, current_order);
expand(zone, page, order, current_order, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}
static inline struct page *get_page_from_free_area(struct free_area *area,
int migratetype)
{
return list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
}Shaping Heap[3]
Now let’s talk about how to arrange the heap layout for the OOB write. As we already knew, the page allocator keeps a free_list for each order in free_area. Pages come and go in free_list, there is no guarantee that two page blocks in the same free_list are contiguous, thus even we allocate the same order of pages consecutively, they might still be far away from each other. In order to shape the heap correctly, we have to make sure all pages in one free_list are contiguous. To do so, we need to drain the free_list of the target order and cause them to borrow page blocks from the higher order. Once it borrows pages from a higher order, two consecutively allocations will split the higher-order pages, and most importantly, the higher-order pages are a chunk of contiguous memory.
Mitigating noise
One challenge for shaping heap is how to mitigate the noise? We noticed that some kernel daemon processes constantly allocate and free pages back and forth, lower-order pages can merge into higher-order, higher-order pages will split to fulfill the needs of the lower order, these create tons of noise while doing heap grooming. In our case, we try to do heap grooming with order-3 pages, but order-2 always requests and splits order-3 pages or sometimes order-2 pages are merged back to order-3’s free_list.
To mitigate this noise, I did something shown below:
- drain the freelist of order 0, 1, 2.
- allocate tons of order-2 objects(assume it’s N), by doing so, order 2 will borrow pages from order 3.
- free every half of objects from step 2, hold the other half. This creates N/2 more object back to order-2’s freelist.
- free all objects from step 1
In step 3, we don’t want to free all of them because they will go back to order 3 when they find adjacent pages in the order-2’s free_list. Freeing every half of order-2 pages will put them in order-2’s free_list forever. This method creates N/2 more pages in order-2’s free_list and thus prevents order 2 from borrowing/merging pages from/to order 3. This strategy protects our heap grooming.

Leaking KASLR offset
Candidate 1: struct msg_msg
The first step for exploiting is to leak the KASLR offset. One simple idea that came to my mind is using struct msg_msg to create an arbitrary read. The basic idea of this approach is overwriting the m_ts field in struct msg_msg which changes the length of the message (struct msg_msgseg). m_ts controls the length of the message pointed by next pointer. By overwriting m_ts, we can read out-of-bound on next pointer.
struct msg_msg {
struct list_head m_list;
long m_type;
size_t m_ts; /* message text size */
struct msg_msgseg *next;
void *security;
/* the actual message follows immediately */
};
struct msg_msgseg {
struct msg_msgseg *next;
/* the next part of the message follows immediately */
};While I was testing, I realized the garbage bytes that append to the tail totally corrupt this approach. When we are overwriting the m_ts field, the garbage bytes will also overwrite a few bytes in next pointer. Since the next is corrupted, the out-of-bounds read makes no sense. (OOB read from the address pointed by this next pointer.

Candidate 2: struct user_key_payload
I was stuck at this phase for a while, I need to find some other structures that don’t have a critical field right behind the field I plan to overwrite, otherwise, the garbage data will corrupt it. I read a few papers[6] to gain some insights, eventually, I found this structure called user_key_payload fits all my requirements.
struct user_key_payload {
struct rcu_head rcu; /* RCU destructor */
unsigned short datalen; /* length of this data */
char data[] __aligned(__alignof__(u64)); /* actual data */
};rcu pointer can be safely set to NULL, datalen is the length field we plan to overwrite, garbage data corrupt several bytes in data[], which is fine since they are just pure data.
One realistic constraint of this structure is that normal users on Ubuntu have a per-user hard limit for how many keys you can have and how many bytes in total you can allocate. As shown in the picture below, Ubuntu allows a normal user to have a maximum of 200 keys and 20000 bytes payload in total.

This limitation makes the exploit become a little bit tricky. Let’s take a look at the preliminary heap layout again. The vulnerable buffer overflows to the adjacent memory (Victim SLAB in the picture). In order to allocate a valid slab on this victim memory, the slab size must be 8 pages. On Ubuntu, only kmalloc-2k, kmalloc-4k, and kmalloc-8k have the order-3 slabs.
I decided to fill the victim SLAB with kmalloc-4k objects, so it makes the minimal size of the user_key_payload to be 2049 bytes (round up to 4k). For kmalloc-4k, each slab has 8 objects. To fill the whole slab with user_key_payload, we have to consume 2049*8=16392 bytes. Remember we have only 20000 bytes in total, and thus there is only one user_key_payload left ((20000-16392)/2049=1). To conclude, we have only two slabs for heap fengshui, which gives us a very weak fault tolerance, any noise could break our fengshui.
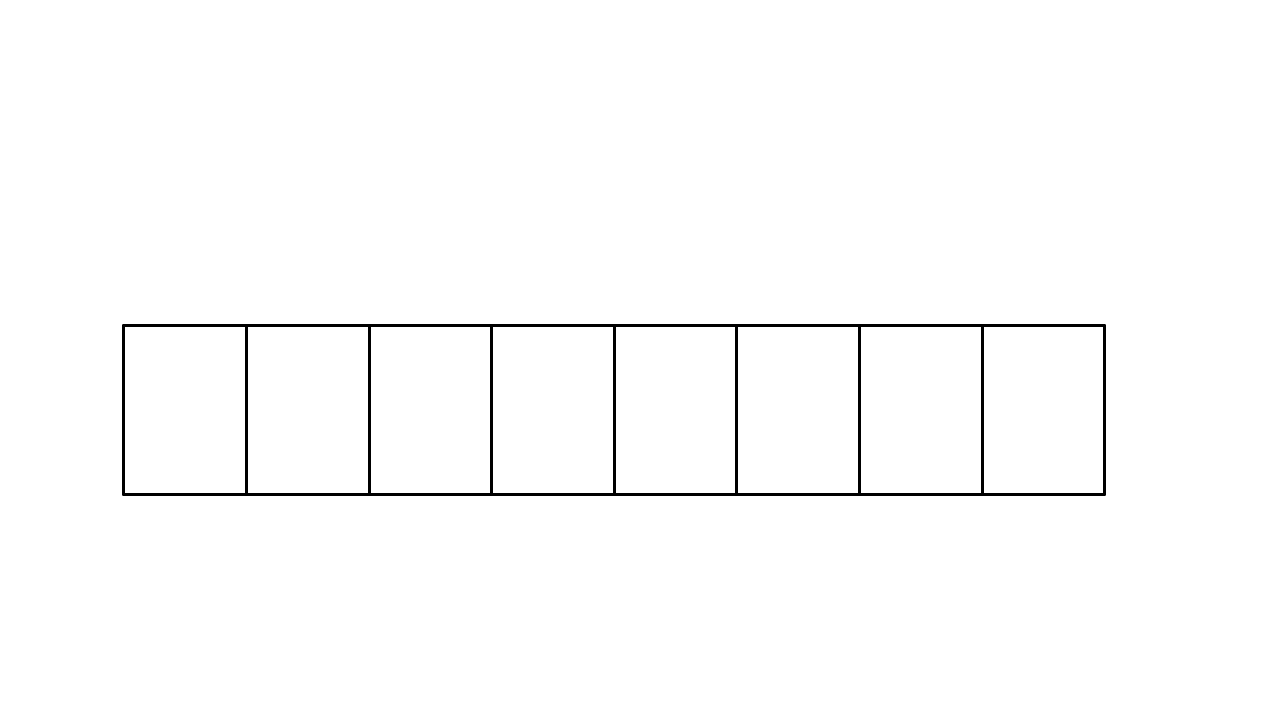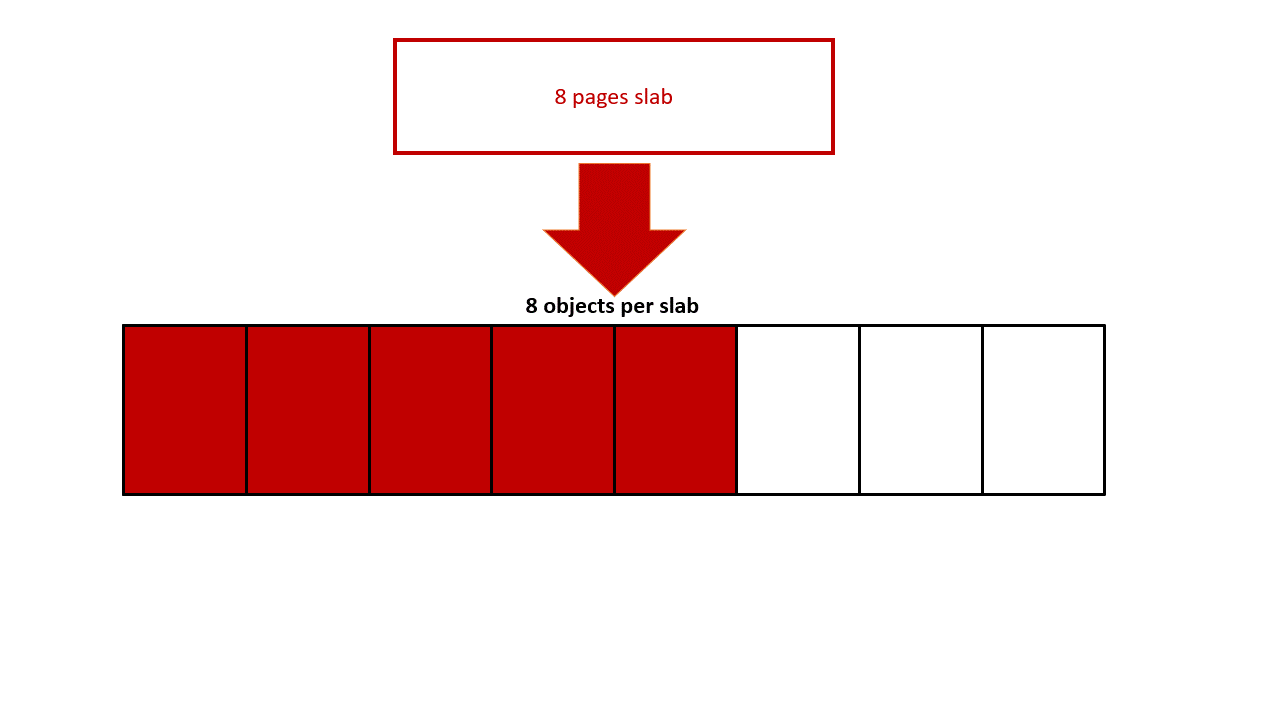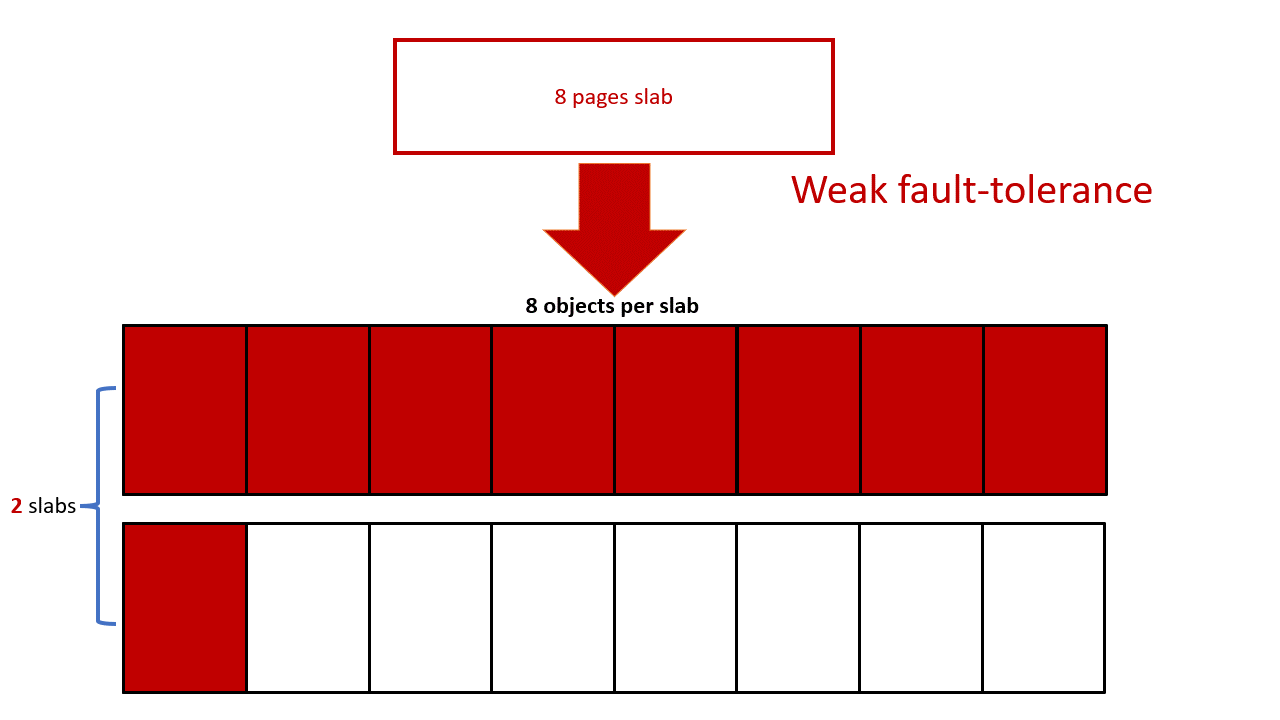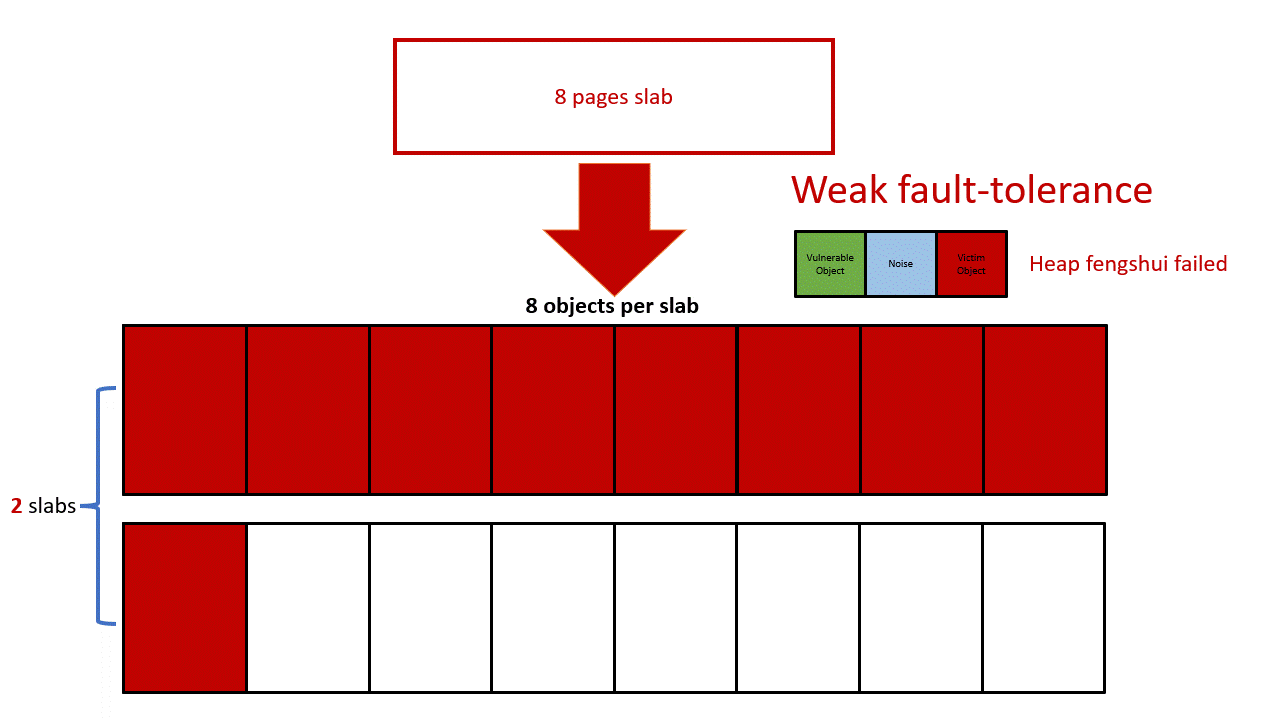
To mitigate this problem, I choose a one user_key_payload per slab approach. Every time I allocate only 1 user_key_payload in each slab and fill the rest of the slab with other objects. user_key_payload‘s position could be arbitrary in the slab due to the freelist randomization. It’s fine in our case, the out-of-bounds write can overwrite the entire slab (8 pages) which will eventually cover the user_key_payload object. With this approach, I can create 9 slabs instead of 2 for the heap fengshui, and it succeeds as long as one slab is in the right place.

What to read?
We have the user_key_payload in place now, let’s start thinking about what kernel object we plan to leak. The simplest way is to put an object with a function pointer next to user_key_payload, then we will leak the KASLR offset by calculating the difference of the function pointer with its address in symbol file. However, I really want to demonstrate the arb read & write techniques from this amazing post, and that’s why I choose to leak the correct next pointer of struct msg_msg.
If I have a correct next pointer, then later I can overwrite m_ts and replace next pointer without worrying corrupt anything (security pointer will be corrupted when overwriting next pointer, but security pointer has no use on Ubuntu, and it’s always zero).
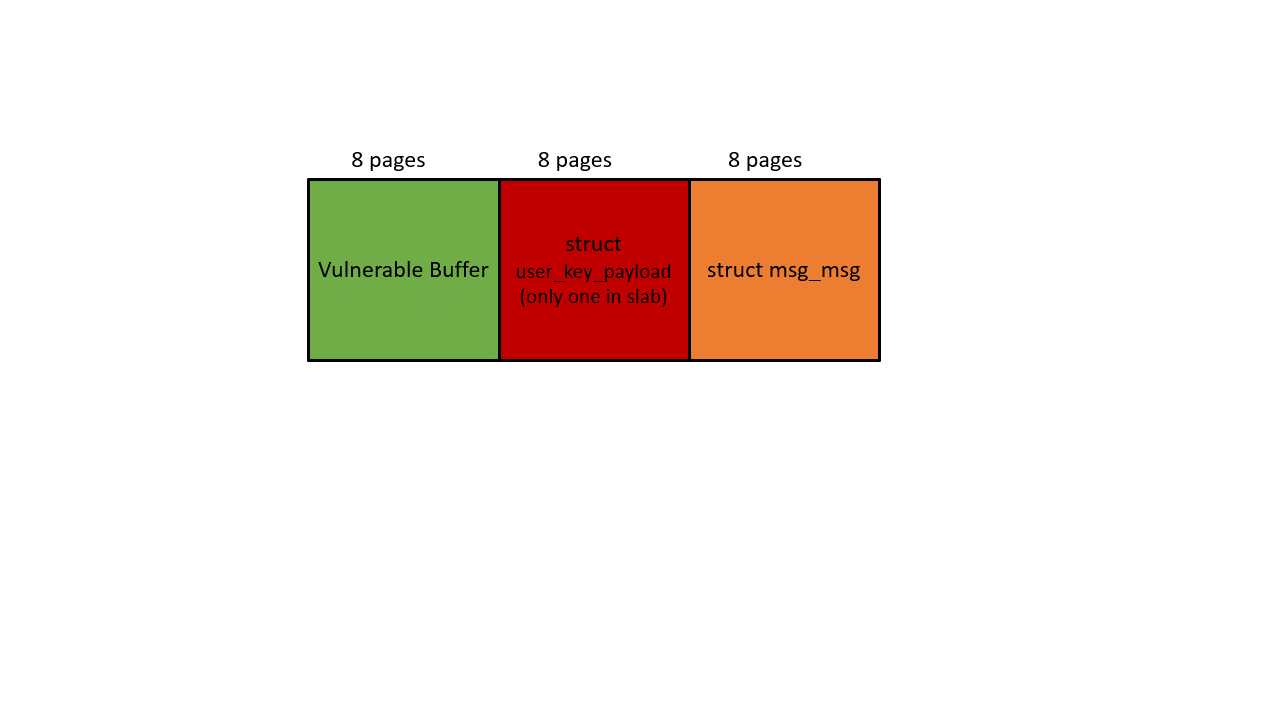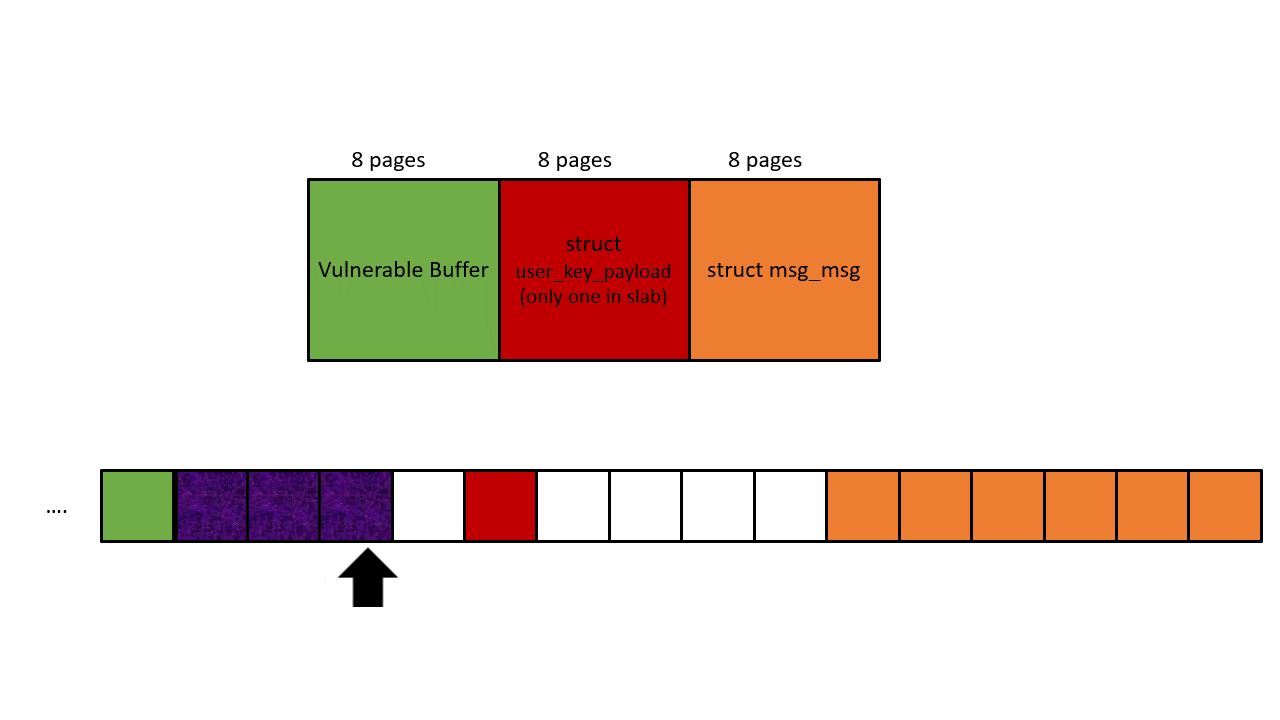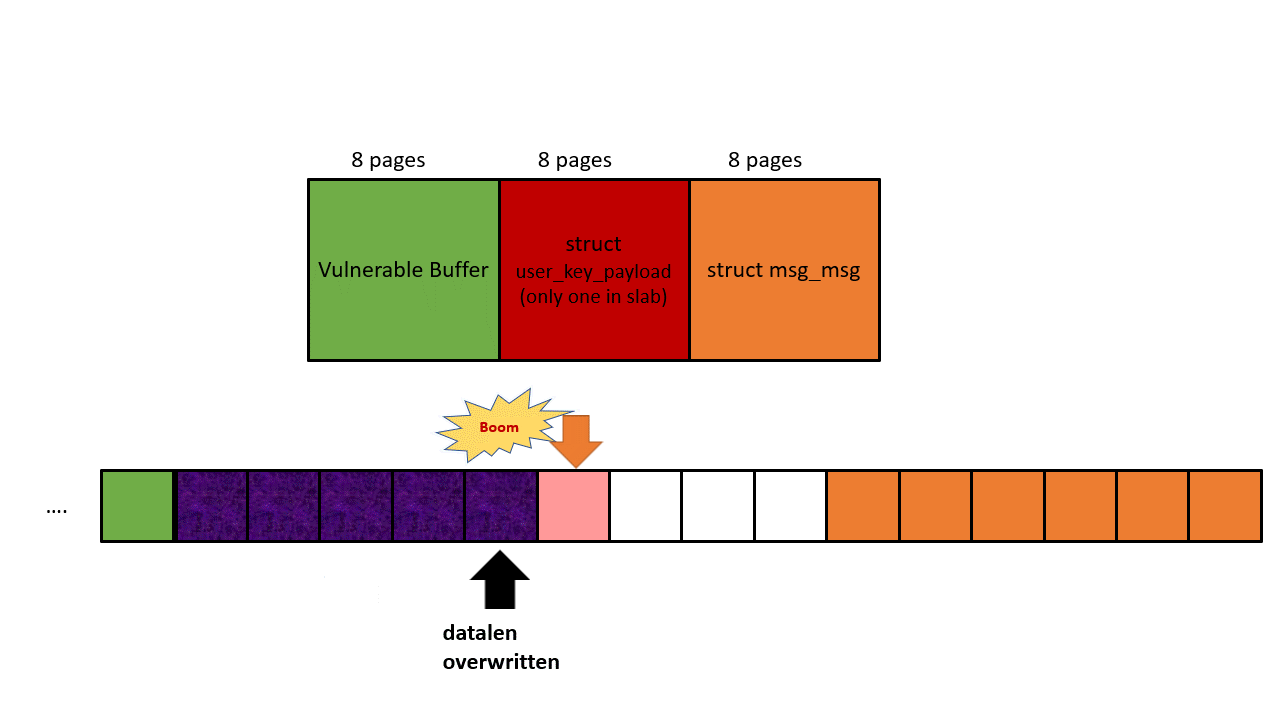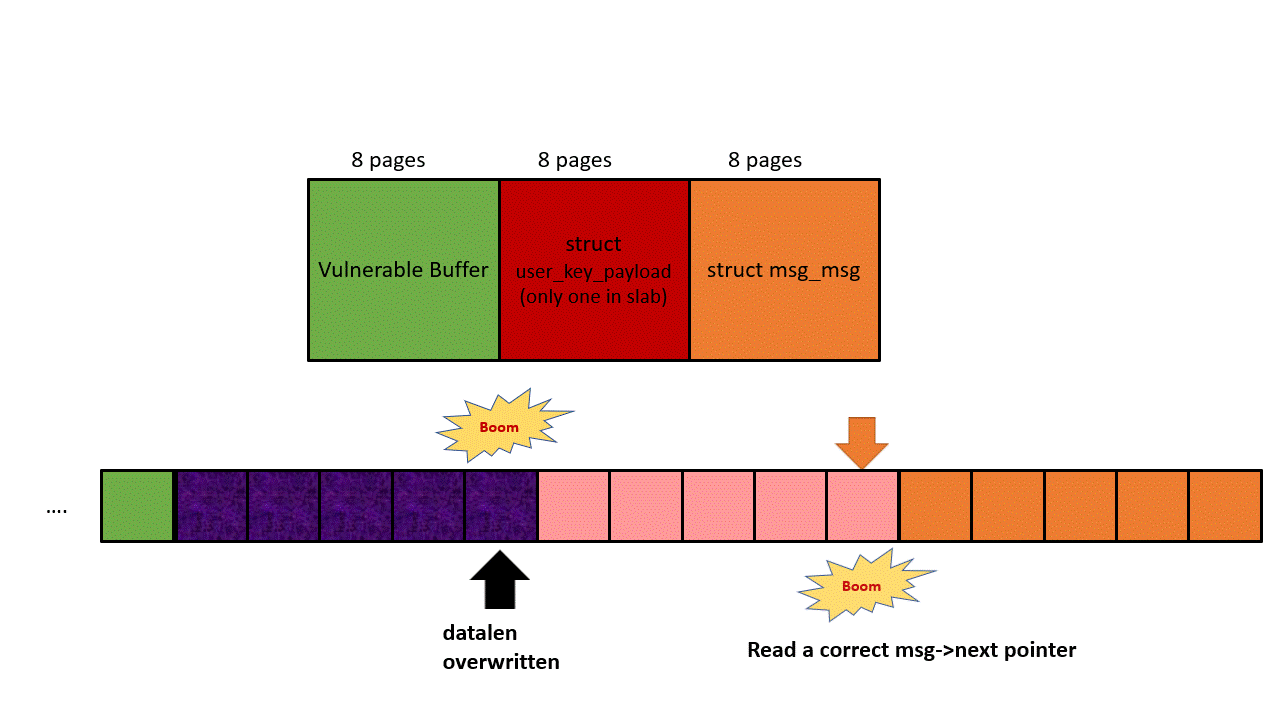
Phase 1: Leak a correct next pointer from struct msg_msg
The heap layout is shown in the picture below. The black arrow represents OOB write, the orange arrow represents OOB read. First, we use the initial OOB write to overwrite the datalen of struct user_key_payload, and then achieve an OOB read by reading the payload of the corrupted struct user_key_payload, our target is the next pointer in struct msg_msg.
Since we will use this next pointer for KASLR leaking later, we have to prepare tons of struct seq_operations along with struct msg_msgseg. Both structures should fall to kmalloc-32, and this gives the msg size a constraint: 4056 bytes to 4072 bytes. It’s because only 4096- 48(header of msg_msg) bytes will be put into the main msg body, and the rest goes to the linked list maintained by next pointer. To make sure the next pointer points to kmalloc-32, the data in struct msg_msgseg cannot exceed 32-8(header of msg_msgseg) bytes and cannot less than 16-8 bytes (otherwise goes to kmalloc-16). If you still cannot understand this, check out this post.
To increment the success rate and mitigate the noise, we create 9 pairs of such heap layout (9 is the most amount of user_key_payload that I can allocate within kmalloc-4k), as long as one pair succeeds, we will get the correct next pointer of struct msg_msg.

Phase 2: Leak KASLR offset
Once we have the correct next pointer, we enter phase 2. We create another heap layout to leak the KASLR offset. struct seq_operations is a good candidate. We use the initial OOB write to overwrite the m_ts (the length of the message) and next pointer (the address of the message), thus we will read the function pointer from struct seq_operations.
So my leaking step is:
Phase 1
- Allocate tons of 8-page buffer to drain order-3’s
free_list. Then order-3 will borrows pages from higher-order which makes them contiguous. - Allocate three contiguous 8-page dummy objects.
- Free the second dummy object, allocate an 8-page slab that contains 1
struct user_key_payloadand 7 other objects. - Free the third dummy object, allocates an 8-page slab that is full of
struct msg_msg. The size of the message must be in the range of 4056 to 4072 in order to make struct msg_msgseg falls to kmalloc-32 - Allocate tons of struct seq_operations. Those structures will be in the same slab with struct msg_msgseg that we allocate in step 4.
- Free the first dummy object, allocates the vulnerability buffer, and start out-of-bounds write, we plan to modify the datalen field in struct user_key_payload.
- If step 6 succeeds, retrieving the payload of this user_key_payload will leads to an out-of-bounds read. This OOB read will tell us the content of struct msg_msg including its
nextpointer. - If step 7 succeeds, we now have a correct
nextpointer of astruct msg_msgobject.
Phase 2
- Allocate two contiguous dummy 8-page objects.
- Free the second dummy object, allocate a slab full of
struct msg_msg. - Free the first dummy object, allocate the vulnerable buffer, overwrite the
m_tsfield with a bigger value and also overwrite thenextpointer with the one we got from phase1 step 7. - If phase2 step 3 succeeds, we should have an OOB read on kmalloc-32 memory. It’s very likely that we will read the function pointer from
struct seq_operationsthat were allocated in phase1 step 5. Then we calculate the KASLR offset.
Get Root
Once we leaked the KASLR offset, msg_msg’s arbitrary write becomes a valid option. The idea of this technique[1] is to hang the first copy_from_user from copying user data(line 7), and then change the next pointer(line 11 shows seg comes from msg->next), resume the process, the next copy_from_user would be an arbitrary write (line 17).
struct msg_msg *load_msg(const void __user *src, size_t len)
{
...
// hang the process at the first copy_from_user
// modify the msg->next and resume the process
if (copy_from_user(msg + 1, src, alen))
goto out_err;
// msg->next has been changed to an arbitrary memory
for (seg = msg->next; seg != NULL; seg = seg->next) {
len -= alen;
src = (char __user *)src + alen;
alen = min(len, DATALEN_SEG);
// Now an arbitrary write happens
if (copy_from_user(seg + 1, src, alen))
goto out_err;
}
...
}If you are familiar with userfaultfd, you might know the technique that uses userfaultfd to hang the process. I posted a blog about it around two years ago. Unfortunately, a normal user needs a specific capability to use userfaultfd after kernel v5.11. But now we have another technique to do the same thing. Thanks to Jann[4] for sharing the idea of using FUSE[5]. FUSE is a filesystem for userspace, we can create our own filesystem and map memory on it, all the read and write go through that memory will be handled by our own file system. Therefore, we can simply hang the process in our custom read (copy_from_user read data from userspace) and release it when the next pointer has been changed.

By utilizing the arbitrary write, we overwrite the path of modprobe. modprobe is a userspace program that loads kernel modules. Every time kernel plans to load a module, it does an upcall to userspace and runs modprobe as root to load the target module. To know where the modprobe locates at, kernel has compiled the path in a hard code way, the path of modprobe stores in a global variable modprobe_path.

My exploit changes the modprobe_path to my own program /tmp/get_rooot that runs chmod u+s /bin/bash. When the kernel runs /tmp/get_rooot as root, it changes the permission of /bin/bash, anyone who runs the bash will run it as root.
My steps to get a root shell:
- Allocate two contiguous 8-page dummy object
- Map the message content to FUSE and free the second dummy object, allocate an 8-page slab full of struct msg_msg. Threads would be hanged in this step.
- Free the first dummy object, allocate the vulnerable object, replace the next pointer of the adjacent struct msg_msg with the address of modprobe_path.
- Release the threads that hang in step 2, copy string “/tmp/get_rooot” to modprobe_path
- Trigger the modprobe by running an unknown format file
- Open
/bin/bash, we are root now
Access exploit on my Github
Special thanks to Norbert Slusarek and Zhiyun Qian
Reference
[1] https://www.willsroot.io/2022/01/cve-2022-0185.html
[2] https://www.kernel.org/doc/gorman/html/understand/understand009.html
[3] https://googleprojectzero.blogspot.com/2017/05/exploiting-linux-kernel-via-packet.html
[4] https://bugs.chromium.org/p/project-zero/issues/detail?id=808
[5] https://github.com/nrb547/kernel-exploitation/blob/main/cve-2021-32606/cve-2021-32606.md
38 Comments
Join the discussion and tell us your opinion.
大佬你好,请问博客中的gif图片是如何制作的?
大佬问一下我运行完poc一直./run.sh:line7:./poc:not such file or directory
./run.sh:line8:kill:(5342) – no such process
大佬你好,我是在ubuntu-20.4环境中,手动对5.13.0内核进行编译并替换,保持跟您博文中的内核版本一致。但是我这边始终无法复现,请问是哪里配置错误了吗?
我的环境如下:
$ uname -a
Linux ubuntu 5.13.0 #2 SMP Sun Jul 3 05:08:42 PDT 2022 x86_64 x86_64 x86_64 GNU/Linux
运行后的无法得到root,log如下:
$ ./poc
Kernel version 5.13.0
0xffffffff81347670 single_start
0xffffffff81347690 single_next
0xffffffff813476b0 single_stop
0xffffffff8266dfc0 modprobe_path
start filling lower order
[+] 9 waiting for free
[+] 8 waiting for free
[+] 7 waiting for free
[+] 6 waiting for free
[+] 4 waiting for free
[+] 2 waiting for free
[+] 3 waiting for free
[+] 0 waiting for free
[+] 5 waiting for free
[+] 1 waiting for free
Released free lock
[+] 9 free done -> 9
[+] 8 free done -> 8
[+] 7 free done -> 7
[+] 6 free done -> 6
[+] 4 free done -> 5
[+] 2 free done -> 4
[+] 3 free done -> 3
[+] 0 free done -> 2
[+] 5 free done -> 1
[+] 1 free done -> 0
fill lower order done
[+] spraying 4k objects
start oob write
[-] 1/9 threads hang
[-] 2/9 threads hang
[-] 3/9 threads hang
[-] 4/9 threads hang
[-] 5/9 threads hang
[-] 6/9 threads hang
[-] 7/9 threads hang
[-] 8/9 threads hang
$
Hi,
从uname上看这是七月的新版本,漏洞已经被修复了,如果要尝试复现漏洞,建议切换到3月的发行版。并且确保该commit(补丁)不在内核代码中:
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=ebe48d368e97d007bfeb76fcb065d6cfc4c96645
果然用ubuntu-21.10能够复现。但是我在ubuntu-21.10下,使用自己编译的5.13.0内核就不能复现。看了poc,需要了补的知识点有点多~~~~~
大佬 我把自己编译内核的debug选项取消就可以复现,不知道啥原因。这个poc对cpu架构敏感吗?我放到arm64上复现,目前还没成功。5.4.18内核
同学,你这篇文章我想翻译到自己的博客上,可以么
注明引用出处和作者即可
Hello,
Awesome write-up, i appreciate your work.
Is CONFIG_HARDENED_USERCOPY enabled on your Ubuntu 21.10 env.?
Didn’t it mitigate arbitrary write primitive of msg_msg ? (because msg_msg uses copy_from_user)
Yes, CONFIG_HARDENED_USERCOPY is enabled. But I didn’t even notice this security feature exist until you bring it up. Several thoughts about why it doesn’t mitigate the arbitrary write.
Since null_skcipher_crypt function was added into kernel after v5.1-rc1, would CVE-2022-27666 be triggered in Linux v4 kernel?
The null_skcipher_crypt only serves as the manifestation, but not the root cause of this vulnerability. You should check whether if there are any other use sites of the vulnerability object, which show different manifestations.
The stage of environment setup is too difficult, how could you finish it? You are very strong. Is the setup code for netlink? Or for the vulnerability? Where could I learn the meaning of the environment setup code?
Anything besides exploit part was generated by syzkaller, including the environment setup. I did rewrite the core code that triggers the bug (see function loop()) for a better understanding of this vulnerability. You don’t have to know how exactly the environment was setup, if you still plan to do that, check out this implementation from syzkaller
In your writeup, I saw that you can spray 9 user_key_payload in each 8-page. And in exp, you use two_loop->proc_mutex to maintain 9 processes and each process tries once. But I could not understand the execution principle of these 9 processes. How do you achieve this.
Proc id N_PROCS is the master of all other procs, it acquires and releases the locks of all other procs (0 <= id < N_PROCS). For each proc, it executes from line 1560 to line 1587 and hangs. After all procs were hanged, master proc release the lock again, they try OOB write and hang again on line 1646
Amazing blog post. Thanks for sharing!
What did you use to draw these animated diagrams? They are awesome.
Hi, thanks. I use Microsoft PowerPoint
I really enjoyed reading your blog post! You did a great job explaining and the graphics and animations helped a lot as well. What did you use to make the animations?
Lmao, Microsoft Power Point
Does this affect centos and red hat 7/8 ?
As long as they have esp6 modules compiled, it should be affected.
how can you know if esp6 modules are compiled?
grep the kernel configuration file with
CONFIG_INET6_ESPCan this vulnerability be remote exploited?
Haven’t tested yet, it could be an interesting aspect! This vulnerability is triggered through sendmsg, it’s possible to trigger it remotely.
I am confused a Lil bit there was a buffer overflow as buffer was of fixed 8 page sized and you gave 16 pages. If you send 16 pages it will overwrite adjancent memory but how did it overwrite struct msg_msg how did you knew where was this struct in memory
The heap grooming help arrange the memory layout. The layout we want is -> | vul buffer | msg_msg |. To do so we just need to allocate two dummy 8-page objects and free them sequentially, and allocate msg_msg and vulnerable buffer, the overflow should write to the adjacent memory which is the msg_msg. It’s basically the same technique from figure 8.
Thanks a lot i am very happy you are the first person who replied when I asked a doubt about something on their webpage. Thanks a lot it matters hope you will help again if i will not be able to understand that heap grooming part. But I will try to do it
Sure, I’ll be happy to answer your questions.
Ya i i know about heap grooming to make use of heap way you want but mine problem is with structures you are using for aslr leak there is how much possibility that the pointer in struct will get cpu control as you not know about actual memory map but allocating struct in those heap/pages slabs
You can simply Pin only one CPU for a process. https://github.com/plummm/CVE-2022-27666/blob/9c8b53149918e32ca16803c747310a833e42b949/poc.c#L1939
If i am not wrong what you are actually doing in first phase is have 16 pages message last 8 pages a vulnerable buffer and in that you write user_key_payload and and other object in that one slab in the hope tht if there was struct user_key_payload in any page than this out of bound write will overwrite it and when tht struct will be used your phase 1 will be completed. But you not exactly know where in memory that struct could be am I right.
I kinda had some difficulties understanding you. I think figure 8 explains how the `user_key_payload` and `msg_msg` be adjacent to the vulnerable buffer. This is the basic use of heap grooming.
Does this affect Android and ChromeOS?
Haven’t checked, as long as esp6 is enabled on Android and ChromeOS, this should affect them.
我看大佬博客之前有中文的文章,应该是中国人,直接用汉语问了,请问有能直接触发漏洞的简易版poc代码供参考一下吗,大佬的提权exp 2000多行有点看不动,而且在我自己编译的内核跑大佬的exp 好像跑不到关键的部分,断不住关键函数(我太菜了)…看漏洞溢出部分的代码,不太理解这里的溢出根因,因为我的理解是溢出是拷贝时候没有校验长度的问题,但补丁修复的却是申请缓存的部分…
PoC 1271行之前是环境的setup不重要。如果是要在自己编译的kernel里跑,需要提供对应的符号文件,PoC用到了几个符号:single_start, single_next, single_stop 和 modprobe_path。在PoC 111行开始把地址修改正确。